
TMDb API; A How-To Guide
Goal
My overall goal for my last project of the semester was to focus on something that I was passionate about, so the film industry was an obvious choice. With a full EDA to follow, my aim here is to explain how I got the data that I did, and what I did to manipulate it to ensure it was usable for future analysis.
Finding the Data
This is where my dear friend ChatGPT comes into play. ALthough an imperfect AI (which most are), I believe that having it dig through search engines for you to save you time is one of the best ways to take advantage of tools such as these. When I decided that I wanted to focus on the film industry, I asked ChatGPT what APIs it could find for me to use, leading me to The Movie Database (TMDb) API.
Wait, What’s an API?
An API, which stands for Application Programming Interface, is a set of rules for interacting with software applications; in other words, APIs serve as bridges between an application and a certain database. Here, it is helping my application access data from TMDb, allowing me to programmatically query specific information about movies. APIs facilitate the EDA process, specifically generating data, which is the main reason I chose to use one for this project.
Is This Ethical?
Using the TMDb API for educational purposes is a practical application of technology in learning environments. This approach adheres to ethical standards by focusing on explicit academic use, with the primary goal being a further in my understanding of APIs and web scraping. It’s important to respect the API’s terms of service, which includes using the data responsibly, not overloading the server with requests, and ensuring no infringement on copyright or privacy occurs. The educational use of the TMDb API offers a real-world experience in handling and interpreting data, while also instilling a sense of responsibility and ethics in data usage. By focusing on education, we underscore the importance of ethical considerations in tech use, ensuring that our exploration into cinematic univserses is both informative and conscientious.
Scraping the Data
The first step in any project is to load the necessary libraries. For this project, there are quite a few:
import pandas as pd
import numpy as np
import urllib.parse
import matplotlib.pyplot as plt
import seaborn as sns
from bs4 import BeautifulSoup
import requests
from collections import defaultdict
from collections import Counter
import itertools
Using an API requires a key, which is essentially a password that gives you access to the data that you’re obtaining via that API. The TMDb one was free (!), but some of them require payments or authorization, so choosing one that fits your needs is important. I would also like to note that API keys, though they play an integral part in your code, should be kept private. My own API key will be absent from this post, but if you wanted to recreate it, you’d have to register for one yourself and load it in like this:
api_key = 'YOUR_KEY_HERE'
The very first thing I did was define the range of years I wanted to explore, and initialize an empty list where I could store the data:
years = range(1997, 2022)
movies_data = []
Next, I created a function that would grab the director and top-billed cast member of each movie included in my data. I did this using ‘requests’, which is essentially asking for these credits for a specific movie through the API.
def get_director_and_cast(movie_id):
"""Fetch the director and top-billed cast of the movie by movie_id."""
response = requests.get(
f'https://api.themoviedb.org/3/movie/{movie_id}/credits?api_key={api_key}'
)
credits = response.json()
director_name = None
top_billed_cast = []
for crew_member in credits.get('crew', []):
if crew_member['job'] == 'Director':
director_name = crew_member['name']
break
for cast_member in credits.get('cast', [])[:1]: # Get only the top-billed cast member
top_billed_cast.append(cast_member['name'])
return director_name, top_billed_cast[0] if top_billed_cast else None
The TMDb API has an endpoint for credits, which is where the cast and crew data is too, so making the GET request for the credits and from there extracting the director and top-billed cast seemed like the most straightforward route to take.
Next on the agenda was fetching the genres for each film. Similar to how I approached the credits, going through the specific endpoint for genre was the easiest way to approach this.
genres_response = requests.get(
f'https://api.themoviedb.org/3/genre/movie/list?api_key={api_key}'
)
genres_list = genres_response.json()['genres']
genre_id_to_name = {genre['id']: genre['name'] for genre in genres_list}
Next, in an effort to conserve time, I combined the act of retreiving a movie’s revenue and production company (or companies) by creating one function for both actions:
def get_movie_revenue_and_production_companies(movie_id):
"""Fetch revenue and production companies for the movie by movie_id."""
details_response = requests.get(
f'https://api.themoviedb.org/3/movie/{movie_id}?api_key={api_key}'
)
details = details_response.json()
revenue = details.get('revenue', 0)
production_companies = [company['name'] for company in details.get('production_companies', [])]
return revenue, production_companies
The GET request made here, which is then turned into a dictionary called ‘details’, contains most of the data about any particular movie, including the two categories extracted here.
Now this is where the fun begins! Remember way far back where I established a range of years? This is where it finally comes into play. I created a for loop that, for every year within the specified range, will extract the highest-rated movie’s title, year, rating, genre(s), director, top-billed cast, revenue, and production company, up to 500 movies.
for year in years:
# Fetch the top-rated movies for the year with a sufficient number of votes to ensure data reliability
response = requests.get(
f'https://api.themoviedb.org/3/discover/movie?api_key={api_key}&sort_by=vote_average.desc&primary_release_year={year}&vote_count.gte=500&page=1'
)
movies = response.json()['results']
for movie in movies:
movie_id = movie['id']
director_name, top_cast_member = get_director_and_cast(movie_id)
movie_genres = [genre_id_to_name[genre_id] for genre_id in movie['genre_ids'] if genre_id in genre_id_to_name]
revenue, production_companies = get_movie_revenue_and_production_companies(movie_id)
movies_data.append({
'ID': movie_id,
'Title': movie['title'],
'Year': year,
'Rating': movie['vote_average'],
'Genres': movie_genres, # Here we're adding the actual genre names
'Director': director_name,
'Top_Cast_Member': top_cast_member,
'Revenue': revenue,
'Production_Companies': production_companies
# ... other fields
})
if len(movies_data) >= 500:
break
if len(movies_data) >= 500:
break
# Convert to DataFrame
df_movies = pd.DataFrame(movies_data)
df_movies
Et voilà! A beautiful table of film data!
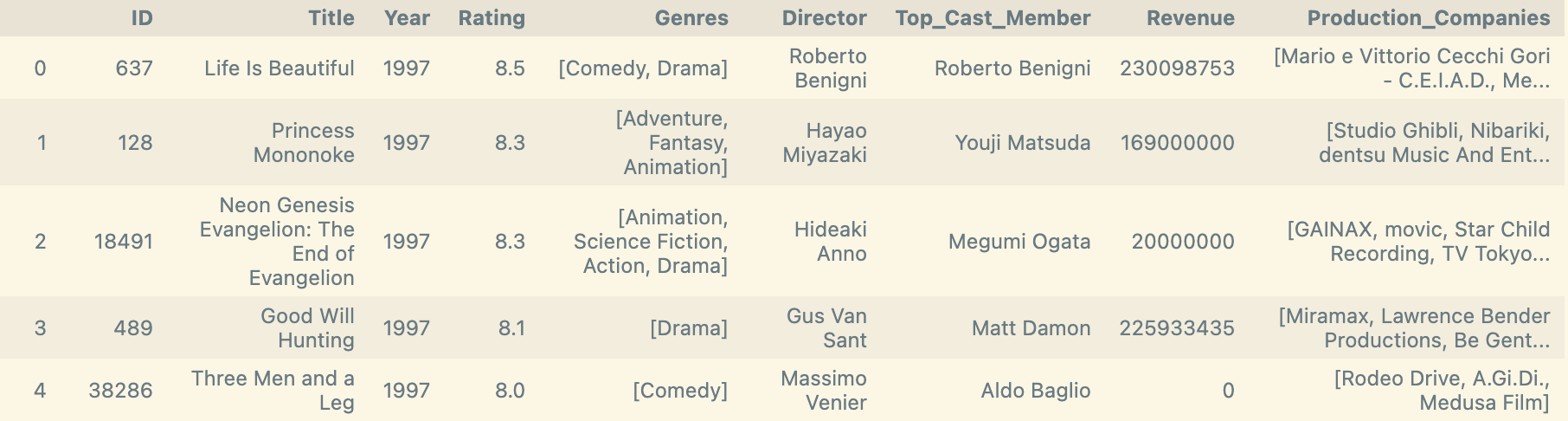
Oh, and I also decided to add a column for the movie’s budget for some of the EDA I’m going to perform, but to see the fruits of that labor you’ll have to head over to my other blog post :) Happy reading!
def get_movie_budget(movie_id):
"""Fetch the budget for the movie by movie_id."""
details_response = requests.get(
f'https://api.themoviedb.org/3/movie/{movie_id}?api_key={api_key}'
)
details_data = details_response.json()
return details_data.get('budget', 0)
df_movies['Budget'] = df_movies['ID'].apply(get_movie_budget)
Check out my GitHub repository for the full code and CSV file of the data!